![]()
[Sep 15, 2025] 100% Real & Accurate Databricks-Certified-Data-Analyst-Associate Questions with Free and Fast Updates
Self-Study Guide for Becoming an Databricks Certified Data Analyst Associate Exam Expert
Databricks Databricks-Certified-Data-Analyst-Associate Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
| Topic 4 |
|
| Topic 5 |
|
NEW QUESTION # 38
Delta Lake stores table data as a series of data files, but it also stores a lot of other information.
Which of the following is stored alongside data files when using Delta Lake?
- A. Table metadata
- B. None of these
- C. Data summary visualizations
- D. Table metadata, data summary visualizations, and owner account information
- E. Owner account information
Answer: A
Explanation:
Delta Lake stores table data as a series of data files in a specified location, but it also stores table metadata in a transaction log. The table metadata includes the schema, partitioning information, table properties, and other configuration details. The table metadata is stored alongside the data files and is updated atomically with every write operation. The table metadata can be accessed using the DESCRIBE DETAIL command or the DeltaTable class in Scala, Python, or Java. The table metadata can also be enriched with custom tags or user-defined commit messages using the TBLPROPERTIES or userMetadata options. Reference:
Enrich Delta Lake tables with custom metadata
Delta Lake Table metadata - Stack Overflow
Metadata - The Internals of Delta Lake
NEW QUESTION # 39
A data engineering team has created a Structured Streaming pipeline that processes data in micro-batches and populates gold-level tables. The microbatches are triggered every minute.
A data analyst has created a dashboard based on this gold-level data. The project stakeholders want to see the results in the dashboard updated within one minute or less of new data becoming available within the gold-level tables.
Which of the following cautions should the data analyst share prior to setting up the dashboard to complete this task?
- A. The gold-level tables are not appropriately clean for business reporting
- B. The streaming cluster is not fault tolerant
- C. The required compute resources could be costly
- D. The streaming data is not an appropriate data source for a dashboard
- E. The dashboard cannot be refreshed that quickly
Answer: C
Explanation:
A Structured Streaming pipeline that processes data in micro-batches and populates gold-level tables every minute requires a high level of compute resources to handle the frequent data ingestion, processing, and writing. This could result in a significant cost for the organization, especially if the data volume and velocity are large. Therefore, the data analyst should share this caution with the project stakeholders before setting up the dashboard and evaluate the trade-offs between the desired refresh rate and the available budget. The other options are not valid cautions because:
B) The gold-level tables are assumed to be appropriately clean for business reporting, as they are the final output of the data engineering pipeline. If the data quality is not satisfactory, the issue should be addressed at the source or silver level, not at the gold level.
C) The streaming data is an appropriate data source for a dashboard, as it can provide near real-time insights and analytics for the business users. Structured Streaming supports various sources and sinks for streaming data, including Delta Lake, which can enable both batch and streaming queries on the same data.
D) The streaming cluster is fault tolerant, as Structured Streaming provides end-to-end exactly-once fault-tolerance guarantees through checkpointing and write-ahead logs. If a query fails, it can be restarted from the last checkpoint and resume processing.
E) The dashboard can be refreshed within one minute or less of new data becoming available in the gold-level tables, as Structured Streaming can trigger micro-batches as fast as possible (every few seconds) and update the results incrementally. However, this may not be necessary or optimal for the business use case, as it could cause frequent changes in the dashboard and consume more resources. Reference: Streaming on Databricks, Monitoring Structured Streaming queries on Databricks, A look at the new Structured Streaming UI in Apache Spark 3.0, Run your first Structured Streaming workload
NEW QUESTION # 40
Which statement about subqueries is correct?
- A. Subqueries can be used like other built-in functions to transform data into different data types.
- B. Subqueries can retrieve data without requiring the creation of a table or view.
- C. Subqueries are not available in Databricks SQL
- D. Subqueries can be used like other user-defined functions to transform data into different data types.
Answer: B
Explanation:
In Databricks SQL, a subquery is a nested query within a larger SQL query that allows for the retrieval of data without the necessity of creating a table or view. This is particularly useful for simplifying complex queries by breaking them down into more manageable parts. Subqueries can be employed in various clauses such as SELECT, FROM, and WHERE to perform operations like filtering, transforming, and aggregating data on-the-fly. This flexibility enhances query efficiency and readability without the overhead of persisting intermediate results as separate tables or views.
NEW QUESTION # 41
In which of the following situations should a data analyst use higher-order functions?
- A. When custom logic needs to be applied at scale to array data objects
- B. When custom logic needs to be applied to simple, unnested data
- C. When custom logic needs to be converted to Python-native code
- D. When built-in functions are taking too long to perform tasks
- E. When built-in functions need to run through the Catalyst Optimizer
Answer: A
Explanation:
Higher-order functions are a simple extension to SQL to manipulate nested data such as arrays. A higher-order function takes an array, implements how the array is processed, and what the result of the computation will be. It delegates to a lambda function how to process each item in the array. This allows you to define functions that manipulate arrays in SQL, without having to unpack and repack them, use UDFs, or rely on limited built-in functions. Higher-order functions provide a performance benefit over user defined functions. Reference: Higher-order functions | Databricks on AWS, Working with Nested Data Using Higher Order Functions in SQL on Databricks | Databricks Blog, Higher-order functions - Azure Databricks | Microsoft Learn, Optimization recommendations on Databricks | Databricks on AWS
NEW QUESTION # 42
What describes Partner Connect in Databricks?
- A. it allows multi-directional connection between Databricks and Databricks partners easier.
- B. it allows for free use of Databricks partner tools through a common API.
- C. It is a feature that runs Databricks partner tools on a Databricks SQL Warehouse (formerly known as a SQL endpoint).
- D. It exposes connection information to third-party tools via Databricks partners.
Answer: A
Explanation:
Databricks Partner Connect is designed to simplify and streamline the integration between Databricks and its technology partners. It provides a unified interface within the Databricks platform that facilitates the discovery and connection to a variety of data, analytics, and AI tools. By automating the configuration of necessary resources such as clusters, tokens, and connection files, Partner Connect enables seamless, bi-directional data flow between Databricks and partner solutions. This integration enhances the overall functionality of the Databricks Lakehouse by allowing users to easily incorporate external tools and services into their workflows, thereby expanding the platform's capabilities and fostering a more cohesive data ecosystem.https://www.databricks.com/blog/2021/11/18/now-generally-available-introducing-databricks-partner-connect-to-discover-and-connect-popular-data-and-ai-tools-to-the-lakehouse?utm_source=chatgpt.com
NEW QUESTION # 43
Which of the following describes how Databricks SQL should be used in relation to other business intelligence (BI) tools like Tableau, Power BI, and looker?
- A. As an exact substitute with the same level of functionality
- B. As a substitute with less functionality
- C. As a complete replacement with additional functionality
- D. As a complementary tool for professional-grade presentations
- E. As a complementary tool for quick in-platform Bl work
Answer: E
Explanation:
Databricks SQL is not meant to replace or substitute other BI tools, but rather to complement them by providing a fast and easy way to query, explore, and visualize data on the lakehouse using the built-in SQL editor, visualizations, and dashboards. Databricks SQL also integrates seamlessly with popular BI tools like Tableau, Power BI, and Looker, allowing analysts to use their preferred tools to access data through Databricks clusters and SQL warehouses. Databricks SQL offers low-code and no-code experiences, as well as optimized connectors and serverless compute, to enhance the productivity and performance of BI workloads on the lakehouse. Reference: Databricks SQL, Connecting Applications and BI Tools to Databricks SQL, Databricks integrations overview, Databricks SQL: Delivering a Production SQL Development Experience on the Lakehouse
NEW QUESTION # 44
Data professionals with varying titles use the Databricks SQL service as the primary touchpoint with the Databricks Lakehouse Platform. However, some users will use other services like Databricks Machine Learning or Databricks Data Science and Engineering.
Which of the following roles uses Databricks SQL as a secondary service while primarily using one of the other services?
- A. Business intelligence analyst
- B. SQL analyst
- C. Data analyst
- D. Data engineer
- E. Business analyst
Answer: D
Explanation:
Data engineers are primarily responsible for building, managing, and optimizing data pipelines and architectures. They use Databricks Data Science and Engineering service to perform tasks such as data ingestion, transformation, quality, and governance. Data engineers may use Databricks SQL as a secondary service to query, analyze, and visualize data from the lakehouse, but this is not their main focus. Reference: Databricks SQL overview, Databricks Data Science and Engineering overview, Data engineering with Databricks
NEW QUESTION # 45
A data analyst wants to create a Databricks SQL dashboard with multiple data visualizations and multiple counters. What must be completed before adding the data visualizations and counters to the dashboard?
- A. The dashboard owner must also be the owner of the queries, data visualizations, and counters.
- B. A SQL warehouse (formerly known as SQL endpoint) must be turned on and selected.
- C. All data visualizations and counters must be created using Queries.
- D. A markdown-based tile must be added to the top of the dashboard displaying the dashboard's name.
Answer: C
Explanation:
In Databricks SQL, when creating a dashboard that includes multiple data visualizations and counters, it is imperative that each visualization and counter is based on a query. The process involves the following steps:
Develop Queries:
For each desired visualization or counter, write a SQL query that retrieves the necessary data.
Create Visualizations and Counters:
After executing each query, utilize the results to create corresponding visualizations or counters. Databricks SQL offers a variety of visualization types to represent data effectively.
Assemble the Dashboard:
Add the created visualizations and counters to your dashboard, arranging them as needed to convey the desired insights.
By ensuring that all components of the dashboard are derived from queries, you maintain consistency, accuracy, and the ability to refresh data as needed. This approach also facilitates easier maintenance and updates to the dashboard elements.
NEW QUESTION # 46
A data analysis team is working with the table_bronze SQL table as a source for one of its most complex projects. A stakeholder of the project notices that some of the downstream data is duplicative. The analysis team identifies table_bronze as the source of the duplication.
Which of the following queries can be used to deduplicate the data from table_bronze and write it to a new table table_silver?
A)
CREATE TABLE table_silver AS
SELECT DISTINCT *
FROM table_bronze;
B)
CREATE TABLE table_silver AS
INSERT *
FROM table_bronze;
C)
CREATE TABLE table_silver AS
MERGE DEDUPLICATE *
FROM table_bronze;
D)
INSERT INTO TABLE table_silver
SELECT * FROM table_bronze;
E)
INSERT OVERWRITE TABLE table_silver
SELECT * FROM table_bronze;
- A. Option D
- B. Option E
- C. Option B
- D. Option A
- E. Option C
Answer: D
Explanation:
Option A uses the SELECT DISTINCT statement to remove duplicate rows from the table_bronze and create a new table table_silver with the deduplicated data. This is the correct way to deduplicate data using Spark SQL12. Option B simply inserts all the rows from table_bronze into table_silver, without removing any duplicates. Option C is not a valid syntax for Spark SQL, as there is no MERGE DEDUPLICATE statement. Option D appends all the rows from table_bronze into table_silver, without removing any duplicates. Option E overwrites the existing data in table_silver with the data from table_bronze, without removing any duplicates. Reference: Delete Duplicate using SPARK SQL, Spark SQL - How to Remove Duplicate Rows
NEW QUESTION # 47
What is used as a compute resource for Databricks SQL?
- A. SQL warehouses
- B. Single-node clusters
- C. Downstream BI tools integrated with Databricks SQL
- D. Standard clusters
Answer: A
NEW QUESTION # 48
After running DESCRIBE EXTENDED accounts.customers;, the following was returned:
Now, a data analyst runs the following command:
DROP accounts.customers;
Which of the following describes the result of running this command?
- A. All files with the .customers extension are deleted.
- B. The accounts.customers table is removed from the metastore, and the underlying data files are deleted.
- C. Running SELECT * FROM accounts.customers will return all rows in the table.
- D. Running SELECT * FROM delta. `dbfs:/stakeholders/customers` results in an error.
- E. The accounts.customers table is removed from the metastore, but the underlying data files are untouched.
Answer: E
Explanation:
the accounts.customers table is an EXTERNAL table, which means that it is stored outside the default warehouse directory and is not managed by Databricks. Therefore, when you run the DROP command on this table, it only removes the metadata information from the metastore, but does not delete the actual data files from the file system. This means that you can still access the data using the location path (dbfs:/stakeholders/customers) or create another table pointing to the same location. However, if you try to query the table using its name (accounts.customers), you will get an error because the table no longer exists in the metastore. Reference: DROP TABLE | Databricks on AWS, Best practices for dropping a managed Delta Lake table - Databricks
NEW QUESTION # 49
A data analyst wants the following output:
customer_name number_of_orders
John Doe 388
Zhang San 234
Which statement will produce this output?
- A. SELECT customerjiame, (order_id) number_of_orders
FROM customers
JOIN orders
ON customers.customer_id = orders.customer_id; - B. SELECT customerjiame, count(order_id)
FROM customers
JOIN orders
ON customers.customer_id = orders.customer_id GROUP BY customerjiame; - C. SELECT customer_name, count(order_id) number_of_orders
FROM customers
JOIN orders
ON customers.customer_id = orders.customer_id USE customer_name; - D. SELECT customer_name, count(order_id) AS number_of_orders
FROM customers
JOIN orders
ON customers.customer_id = orders.customer_id
GROUP BY customer_name;
Answer: D
NEW QUESTION # 50
A data analyst has created a user-defined function using the following line of code:
CREATE FUNCTION price(spend DOUBLE, units DOUBLE)
RETURNS DOUBLE
RETURN spend / units;
Which of the following code blocks can be used to apply this function to the customer_spend and customer_units columns of the table customer_summary to create column customer_price?
- A. SELECT price FROM customer_summary
- B. SELECT function(price(customer_spend, customer_units)) AS customer_price FROM customer_summary
- C. SELECT PRICE customer_spend, customer_units AS customer_price FROM customer_summary
- D. SELECT double(price(customer_spend, customer_units)) AS customer_price FROM customer_summary
- E. SELECT price(customer_spend, customer_units) AS customer_price FROM customer_summary
Answer: E
Explanation:
A user-defined function (UDF) is a function defined by a user, allowing custom logic to be reused in the user environment1. To apply a UDF to a table, the syntax is SELECT udf_name(column_name) AS alias FROM table_name2. Therefore, option E is the correct way to use the UDF price to create a new column customer_price based on the existing columns customer_spend and customer_units from the table customer_summary. Reference:
What are user-defined functions (UDFs)?
User-defined scalar functions - SQL
V
NEW QUESTION # 51
Which of the following describes how Databricks SQL should be used in relation to other business intelligence (BI) tools like Tableau, Power BI, and looker?
- A. As an exact substitute with the same level of functionality
- B. As a substitute with less functionality
- C. As a complete replacement with additional functionality
- D. As a complementary tool for professional-grade presentations
- E. As a complementary tool for quick in-platform Bl work
Answer: E
Explanation:
Databricks SQL is not meant to replace or substitute other BI tools, but rather to complement them by providing a fast and easy way to query, explore, and visualize data on the lakehouse using the built-in SQL editor, visualizations, and dashboards. Databricks SQL also integrates seamlessly with popular BI tools like Tableau, Power BI, and Looker, allowing analysts to use their preferred tools to access data through Databricks clusters and SQL warehouses. Databricks SQL offers low-code and no-code experiences, as well as optimized connectors and serverless compute, to enhance the productivity and performance of BI workloads on the lakehouse. Reference: Databricks SQL, Connecting Applications and BI Tools to Databricks SQL, Databricks integrations overview, Databricks SQL: Delivering a Production SQL Development Experience on the Lakehouse
NEW QUESTION # 52
Query History provides Databricks SQL users with a lot of benefits. A data analyst has been asked to share all of these benefits with their team as part of a training exercise. One of the benefit statements the analyst provided to their team is incorrect.
Which statement about Query History is incorrect?
- A. It can be used to automate query execution on multiple warehouses (formerly endpoints).
- B. It can be used to troubleshoot slow running queries.
- C. It can be used to view the query plan of queries that have run.
- D. It can be used to debug queries.
Answer: A
Explanation:
Query History in Databricks SQL is intended for reviewing executed queries, understanding their execution plans, and identifying performance issues or errors for debugging purposes. It allows users to analyze query duration, resources used, and potential bottlenecks. However, Query History does not provide any capability to automate the execution of queries across multiple warehouses; automation must be handled through jobs or external orchestration tools, not through the Query History feature itself.
NEW QUESTION # 53
Which of the following approaches can be used to ingest data directly from cloud-based object storage?
- A. Create an external table while specifying the DBFS storage path to PATH
- B. Create an external table while specifying the object storage path to FROM
- C. Create an external table while specifying the object storage path to LOCATION
- D. It is not possible to directly ingest data from cloud-based object storage
- E. Create an external table while specifying the DBFS storage path to FROM
Answer: C
Explanation:
External tables are tables that are defined in the Databricks metastore using the information stored in a cloud object storage location. External tables do not manage the data, but provide a schema and a table name to query the data. To create an external table, you can use the CREATE EXTERNAL TABLE statement and specify the object storage path to the LOCATION clause. For example, to create an external table named ext_table on a Parquet file stored in S3, you can use the following statement:
SQL
CREATE EXTERNAL TABLE ext_table (
col1 INT,
col2 STRING
)
STORED AS PARQUET
LOCATION 's3://bucket/path/file.parquet'
AI-generated code. Review and use carefully. More info on FAQ.
NEW QUESTION # 54
Which location can be used to determine the owner of a managed table?
- A. Review the Owner field in the database page using Data Explorer
- B. Review the Owner field in the schema page using Data Explorer
- C. Review the Owner field in the table page using the SQL Editor
- D. Review the Owner field in the table page using Catalog Explorer
Answer: D
Explanation:
In Databricks, to determine the owner of a managed table, you can utilize the Catalog Explorer feature. The steps are as follows:
Access Catalog Explorer:
In your Databricks workspace, click on the Catalog icon in the sidebar to open Catalog Explorer.
Navigate to the Table:
Within Catalog Explorer, browse through the catalog and schema to locate the specific managed table whose ownership you wish to verify.
View Table Details:
Click on the table name to open its details page.
Identify the Owner:
On the table's details page, review the Owner field, which displays the principal (user, service principal, or group) that owns the table.
This method provides a straightforward way to ascertain the ownership of managed tables within the Databricks environment. Understanding table ownership is essential for managing permissions and ensuring proper access control.
NEW QUESTION # 55
A data analyst is processing a complex aggregation on a table with zero null values and their query returns the following result: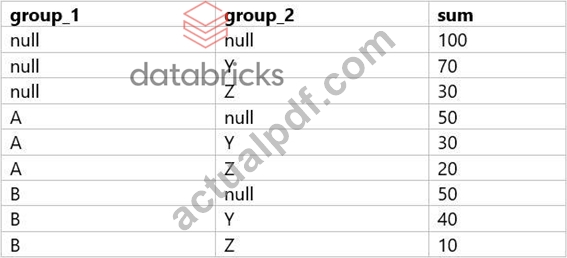
Which of the following queries did the analyst run to obtain the above result?
- A.

- B.

- C.

- D.

- E.

Answer: C
Explanation:
The result set provided shows a combination of grouping by two columns (group_1 and group_2) with subtotals for each level of grouping and a grand total. This pattern is typical of a GROUP BY ... WITH ROLLUP operation in SQL, which provides subtotal rows and a grand total row in the result set.
Considering the query options:
A) Option A: GROUP BY group_1, group_2 INCLUDING NULL - This is not a standard SQL clause and would not result in subtotals and a grand total.
B) Option B: GROUP BY group_1, group_2 WITH ROLLUP - This would create subtotals for each unique group_1, each combination of group_1 and group_2, and a grand total, which matches the result set provided.
C) Option C: GROUP BY group_1, group 2 - This is a simple GROUP BY and would not include subtotals or a grand total.
D) Option D: GROUP BY group_1, group_2, (group_1, group_2) - This syntax is not standard and would likely result in an error or be interpreted as a simple GROUP BY, not providing the subtotals and grand total.
E) Option E: GROUP BY group_1, group_2 WITH CUBE - The WITH CUBE operation produces subtotals for all combinations of the selected columns and a grand total, which is more than what is shown in the result set.
The correct answer is Option B, which uses WITH ROLLUP to generate the subtotals for each level of grouping as well as a grand total. This matches the result set where we have subtotals for each group_1, each combination of group_1 and group_2, and the grand total where both group_1 and group_2 are NULL.
NEW QUESTION # 56
A data engineer is working with a nested array column products in table transactions. They want to expand the table so each unique item in products for each row has its own row where the transaction_id column is duplicated as necessary.
They are using the following incomplete command:
Which of the following lines of code can they use to fill in the blank in the above code block so that it successfully completes the task?
- A. array(produces)
- B. explode(produces)
- C. flatten(produces)
- D. array distinct(produces)
- E. reduce(produces)
Answer: B
Explanation:
The explode function is used to transform a DataFrame column of arrays or maps into multiple rows, duplicating the other column's values. In this context, it will be used to expand the nested array column products in the transactions table so that each unique item in products for each row has its own row and the transaction_id column is duplicated as necessary. Reference: Databricks Documentation I also noticed that you sent me an image along with your message. The image shows a snippet of SQL code that is incomplete. It begins with "SELECT" indicating a query to retrieve data. "transaction_id," suggests that transaction_id is one of the columns being selected. There are blanks indicated by underscores where certain parts of the SQL command should be, including what appears to be an alias for a column and part of the FROM clause. The query ends with "FROM transactions;" indicating data is being selected from a 'transactions' table.
If you are interested in learning more about Databricks Data Analyst Associate certification, you can check out the following resources:
Databricks Certified Data Analyst Associate: This is the official page for the certification exam, where you can find the exam guide, registration details, and preparation tips.
Data Analysis With Databricks SQL: This is a self-paced course that covers the topics and skills required for the certification exam. You can access it for free on Databricks Academy.
Tips for the Databricks Certified Data Analyst Associate Certification: This is a blog post that provides some useful advice and study tips for passing the certification exam.
Databricks Certified Data Analyst Associate Certification: This is another blog post that gives an overview of the certification exam and its benefits.
NEW QUESTION # 57
What is a benefit of using Databricks SQL for business intelligence (Bl) analytics projects instead of using third-party Bl tools?
- A. Automated alerting systems
- B. Computations, data, and analytical tools on the same platform
- C. Simultaneous multi-user support
- D. Advanced dashboarding capabilities
Answer: B
Explanation:
Databricks SQL offers a unified platform where computations, data storage, and analytical tools coexist seamlessly. This integration allows business intelligence (BI) analytics projects to be executed more efficiently, as users can perform data processing and analysis without the need to transfer data between disparate systems. By consolidating these components, Databricks SQL streamlines workflows, reduces latency, and enhances data governance. While third-party BI tools may offer advanced dashboarding capabilities, simultaneous multi-user support, and automated alerting systems, they often require integration with separate data processing platforms, which can introduce complexity and potential inefficiencies.
NEW QUESTION # 58
Which of the following approaches can be used to connect Databricks to Fivetran for data ingestion?
- A. Use Partner Connect's automated workflow to establish a SQL warehouse (formerly known as a SQL endpoint) for Fivetran to interact with
- B. Use Workflows to establish a cluster for Fivetran to interact with
- C. Use Workflows to establish a SQL warehouse (formerly known as a SQL endpoint) for Fivetran to interact with
- D. Use Partner Connect's automated workflow to establish a cluster for Fivetran to interact with
- E. Use Delta Live Tables to establish a cluster for Fivetran to interact with
Answer: D
Explanation:
Partner Connect is a feature that allows you to easily connect your Databricks workspace to Fivetran and other ingestion partners using an automated workflow. You can select a SQL warehouse or a cluster as the destination for your data replication, and the connection details are sent to Fivetran. You can then choose from over 200 data sources that Fivetran supports and start ingesting data into Delta Lake. Reference: Connect to Fivetran using Partner Connect, Use Databricks with Fivetran
NEW QUESTION # 59
......
Databricks-Certified-Data-Analyst-Associate Study Guide Realistic Verified Databricks-Certified-Data-Analyst-Associate Dumps: https://examsboost.actualpdf.com/Databricks-Certified-Data-Analyst-Associate-real-questions.html